|
I am an incoming Nanyang Assistant Professor at Nanyang Technological University (NTU Singapore) in Spring 2026. Currently, I am a postdoctoral fellow at Harvard University supervised by Prof. Hanspeter Pfister. Prior to that, I received my Ph.D. from the Department of Automation at Tsinghua University in 2022, advised by Prof. Jiwen Lu, Prof. Jianjiang Feng , and Prof. Jie Zhou. In 2017, I received my B.S. degree in computer science at Sun Yat-sen University, Guangzhou, China. My research interests mainly include Spatial Intelligence, Neural Rendering, and Physical Intelligence. My long-term goal is to build visually intelligent systems that can perceive, reason about, and interact with the real world. I will be recruiting PhD students in the December 2025 application cycle! I will also be looking for motivated postdocs, visiting students, and research interns to join my group! See Join Us for more details. Email: wanhua016 [AT] gmail [DOT] com CV / Google Scholar / Twitter / LinkedIn |

|
|
|
|
(*Equal Contribution, #Corresponding Author) |
|
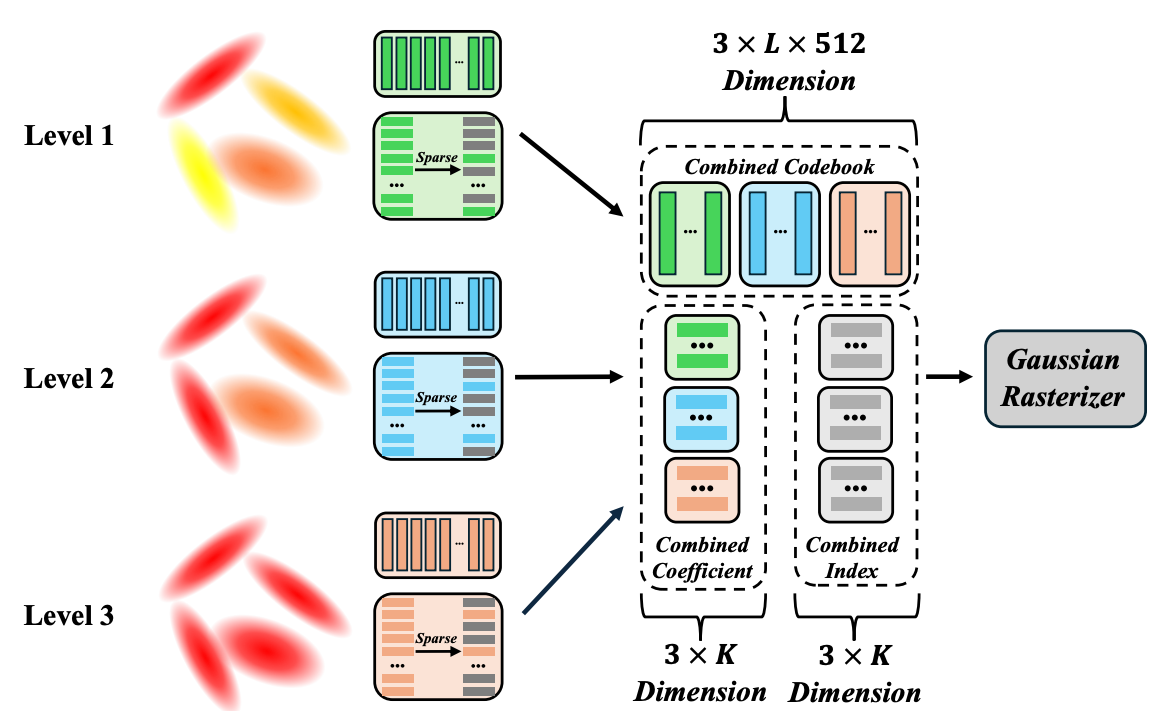
Wanhua Li*, Yujie Zhao*, Minghan Qin*, Yang Liu, Yuanhao Cai, Chuang Gan, Hanspeter Pfister Conference on Neural Information Processing Systems (NeurIPS), 2025 [Website] [arxiv] [Video] [Code] We present LangSplatV2, which achieves high-dimensional feature splatting at 476.2 FPS and 3D open-vocabulary text querying at 384.6 FPS for high-resolution images. |

|
Jixuan Fan*, Wanhua Li*, Yifei Han, Tianru Dai, Yansong Tang International Conference on Computer Vision (ICCV), 2025 [Website] [arxiv] [Video] [Code] We propose Momentum-GS, a momentum-based self-distillation framework that significantly improves 3D Gaussian Splatting for large-scale scene reconstruction. |

|
Wanhua Li*, Renping Zhou*, Jiawei Zhou, Yingwei Song, Johannes Herter, Minghan Qin, Gao Huang, Hanspeter Pfister IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 [Website] [arxiv] [Video] [Code] We present 4D LangSplat, an approach to constructing a dynamic 4D language field in evolving scenes, leveraging Multimodal Large Language Models. |
|
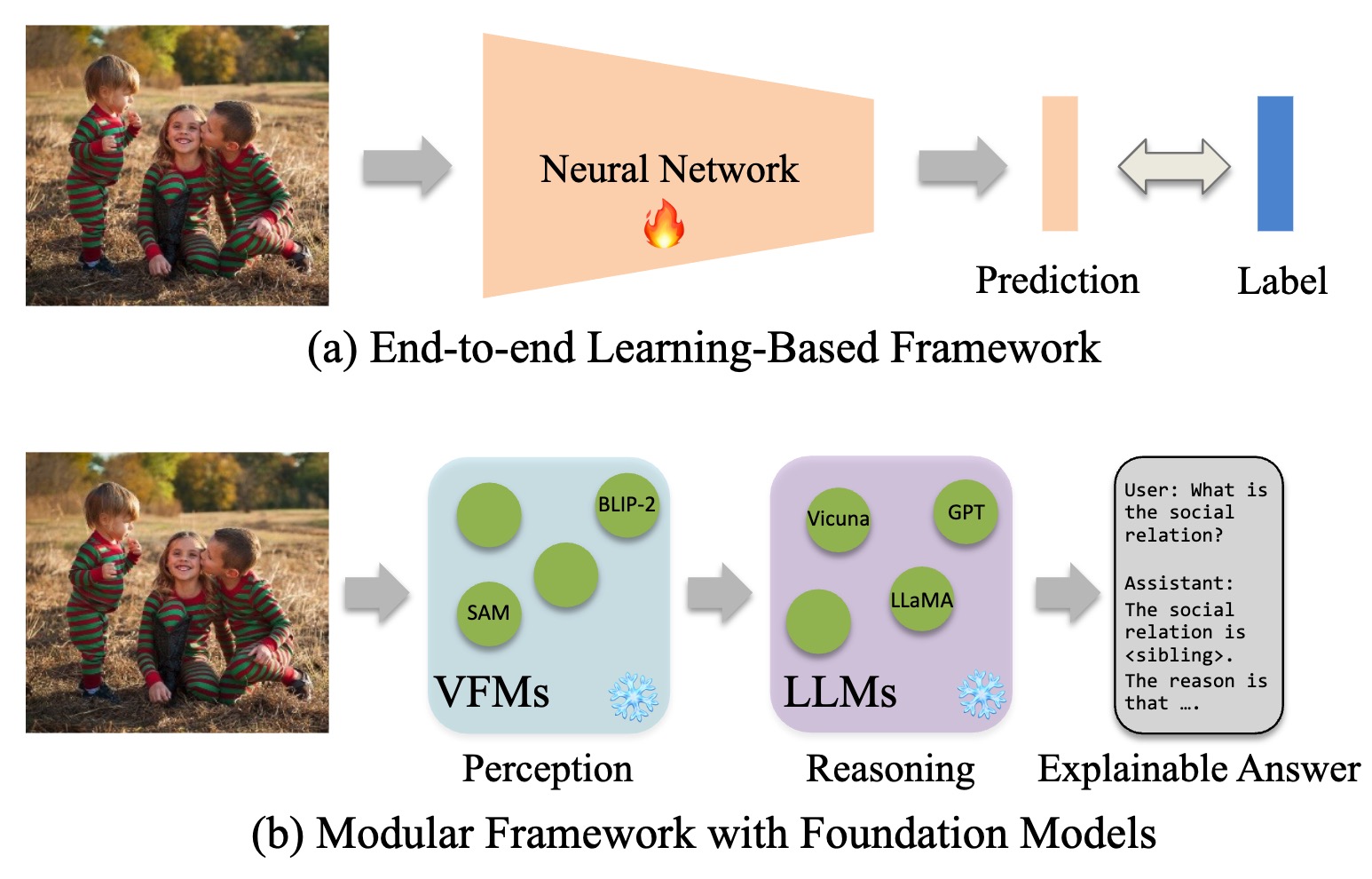
Wanhua Li*, Zibin Meng*, Jiawei Zhou, Donglai Wei, Chuang Gan, Hanspeter Pfister Conference on Neural Information Processing Systems (NeurIPS), 2024 [Website] [arxiv] [Video] [Code] We present SocialGPT, a modular framework with greedy segment prompt optimization for social relation reasoning, which attains competitive results while also providing interpretable explanations. |

|
Minghan Qin*, Wanhua Li*#, Jiawei Zhou*, Haoqian Wang#, Hanspeter Pfister IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024 (Highlight) [Website] [arxiv] [Video] [Code] We ground CLIP features into a set of 3D language Gaussians, which attains precise 3D language fields while being 199 × faster than LERF. |

|
Devaansh Gupta, Siddhant Kharbanda, Jiawei Zhou, Wanhua Li, Hanspeter Pfister, and Donglai Wei IEEE International Conference on Computer Vision (ICCV), 2023 [Website] [arxiv] [Code] [Video] To facilitate using pre-trained models in MMT, we propose CLIPTrans, which transfers the multimodal representations of M-CLIP into a multilingual mBART. |
|
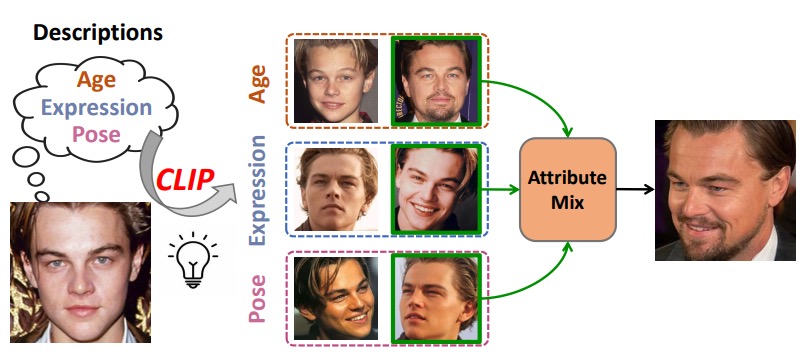
Shuai Shen, Wanhua Li, Xiaobing Wang, Dafeng Zhang, Zhezhu Jin, Jie Zhou, and Jiwen Lu IEEE International Conference on Computer Vision (ICCV), 2023 [Website] [arxiv] [Code] [Video] We propose an attribute hallucination framework named CLIP-Cluster to narrow the intraclass variance caused by different face attributes for face clustering. |
|
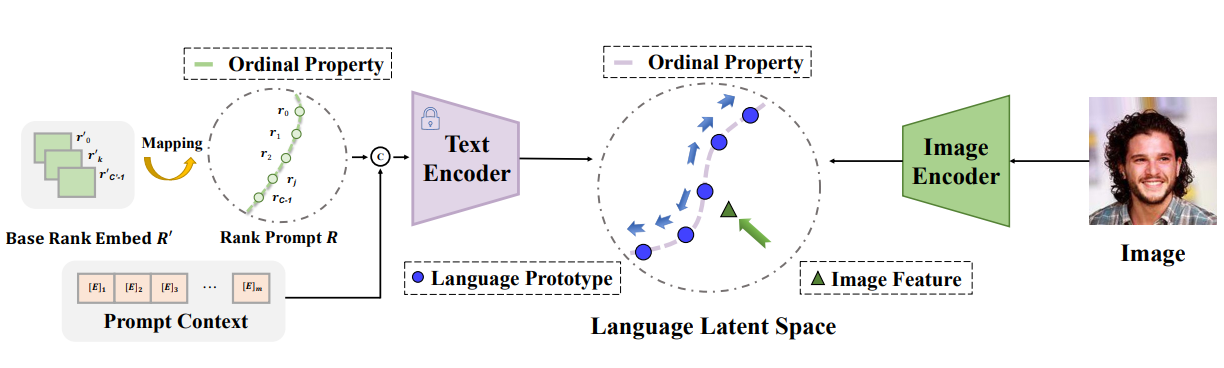
Wanhua Li*, Xiaoke Huang*, Zheng Zhu, Yansong Tang, Xiu Li, Jie Zhou, and Jiwen Lu Conference on Neural Information Processing Systems (NeurIPS), 2022 [Website] [arxiv] [Code] [中文解读] We propose a language-powered paradigm for ordinal regression, which learns the rank concepts from the rich semantic CLIP latent space. |
|
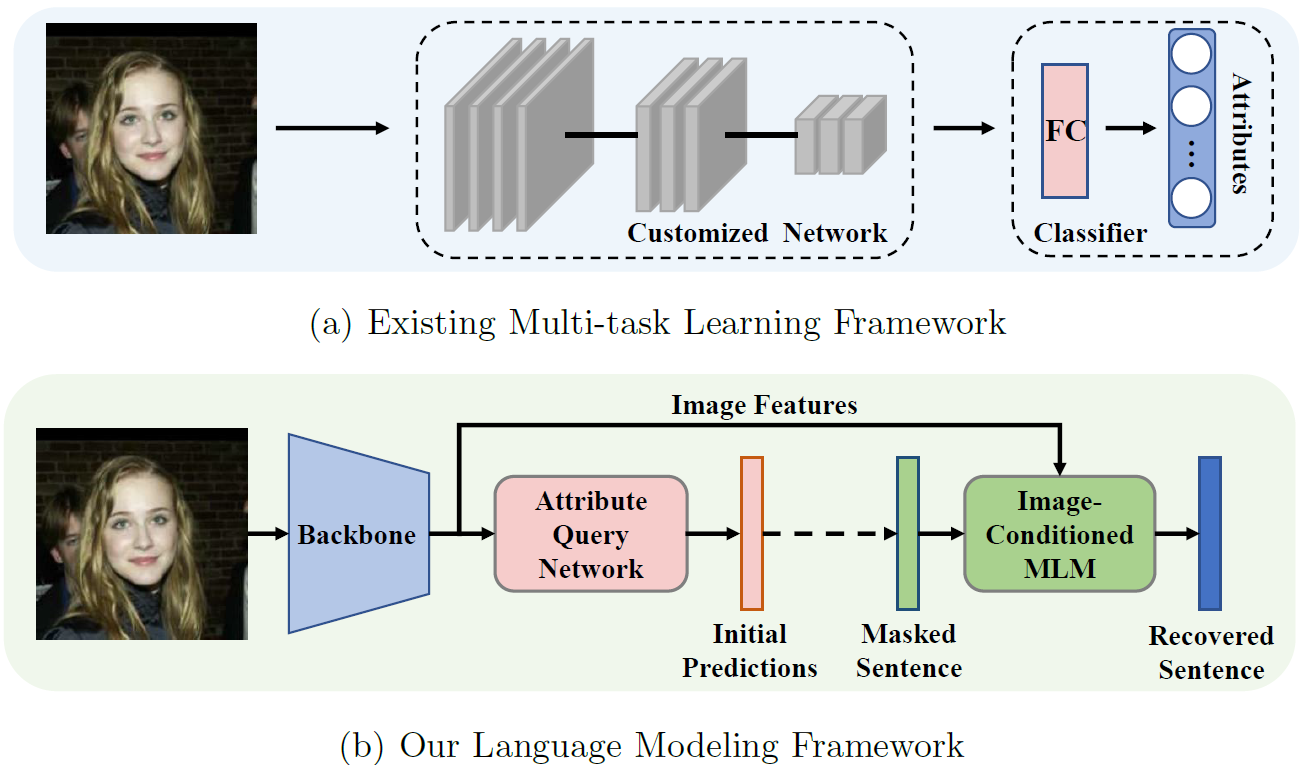
Wanhua Li, Zhexuan Cao, Jianjiang Feng, Jie Zhou, and Jiwen Lu European Conference on Computer Vision (ECCV), 2022 [Website] [arxiv] [Video] [Code] We propose a language modeling framework named Label2Label to model the complex instance-wise attribute relations, which regards each attribute label as a “word” and recovers the label “sentence” based on the masked one. |
|
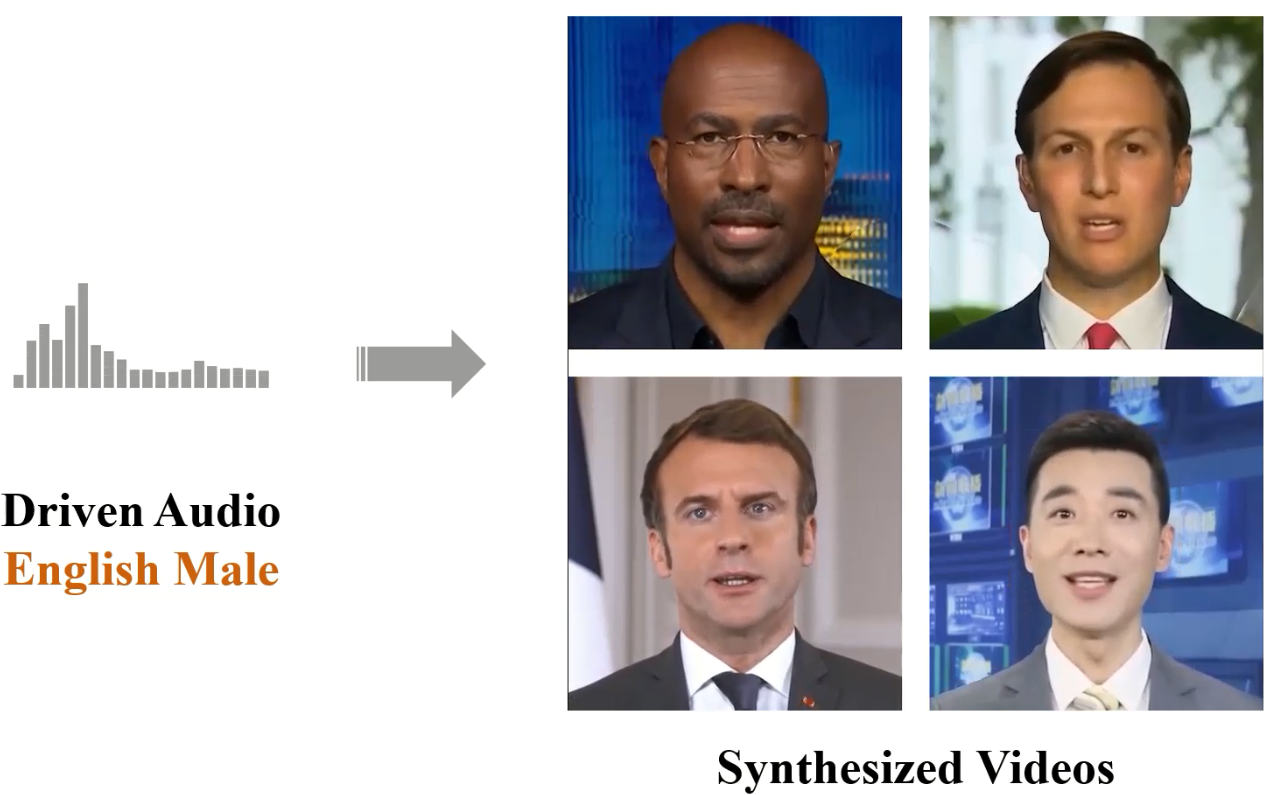
Shuai Shen, Wanhua Li, Zheng Zhu, Yueqi Duan, Jie Zhou, and Jiwen Lu European Conference on Computer Vision (ECCV), 2022 [Website] [arxiv] [Video] [Code] We propose dynamic facial radiance fields conditioned on the 3D aware reference image features. The facial field can rapidly generalize to novel identities with only 15s clip. |

|
Bingyao Yu, Wanhua Li, Xiu Li, Jiwen Lu, and Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 [Paper] [bibtex] We propose a Frequency-Aware Spatiotemporal Transformer for video inpainting detection, which simultaneously mines the traces of video inpainting from spatial, temporal, and frequency domains. |
|
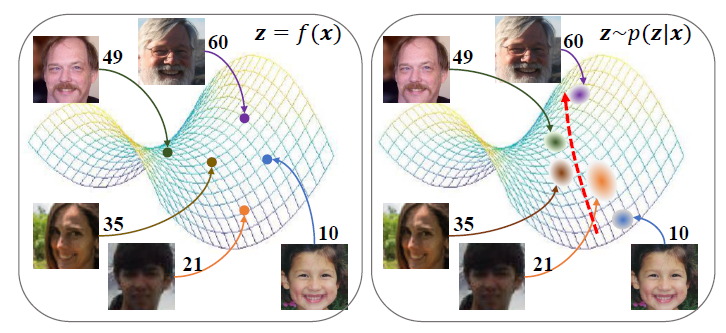
Wanhua Li, Xiaoke Huang, Jiwen Lu, Jianjiang Feng, and Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021 [Website] [arxiv] [Video] [Code] We propose probabilistic ordinal embeddings to empower the present-day regression methods with the ability of uncertainty estimation. |
|
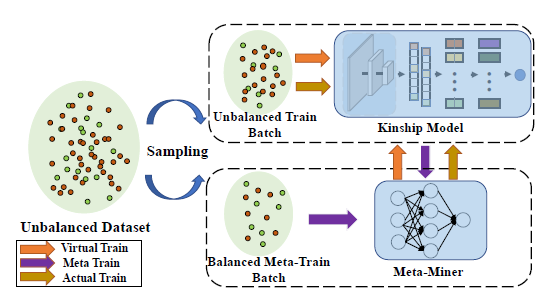
Wanhua Li, Shiwei Wang, Jiwen Lu, Jianjiang Feng, and Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021 [Website] [arxiv] [Video] [bibtex] A Discriminative Sample Meta-Mining strategy is proposed to mine discriminative information from limited positive pairs and sufficient negative samples for kinship verification. |
|
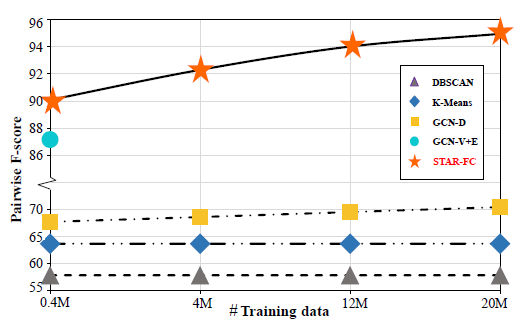
Shuai Shen, Wanhua Li, Zheng Zhu, Guan Huang, Dalong Du, Jiwen Lu, and Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021 [Website] [arxiv] [Code] [Video] It is the first face clustering method to train on very large-scale graph with 20M nodes, and achieve superior inference results on 12M testing data. |
|
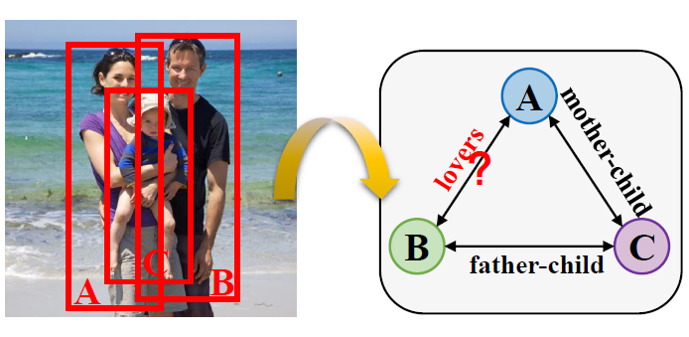
Wanhua Li, Yueqi Duan, Jiwen Lu, Jianjiang Feng, and Jie Zhou European Conference on Computer Vision (ECCV), 2020 [Website] [arxiv] [Video] [Code] A simpler, faster, and more accurate method for social relation recognition. |
|
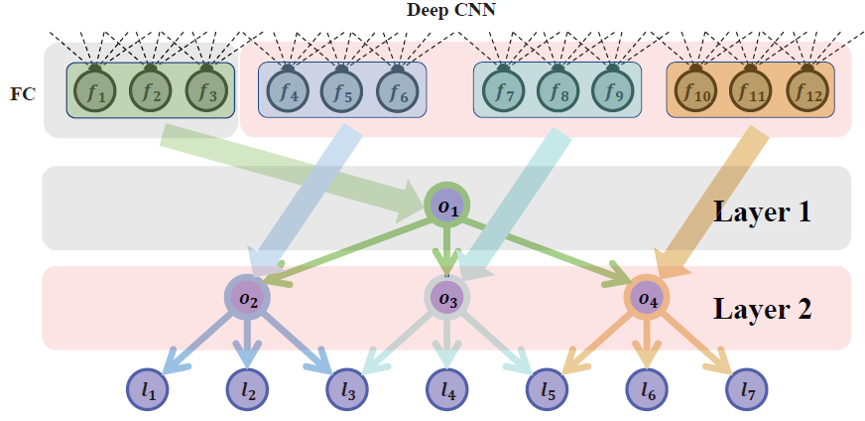
Wanhua Li, Jiwen Lu, Jianjiang Feng, Chunjing Xu, Jie Zhou, Qi Tian IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019 [arXiv] [PDF] [bibtex] We propose BridgeNet for age estimation, which aims to mine the continuous relation between age labels effectively. |
|
|
|
|
|
|